
From Timo Shick and Hinrich Schütze's work "Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference" comes an elegant idea to train for improving performance of language model finetuning in label-scarce settings. Their training procedure, Pattern-Exploiting Training (PET), yields significant gains over a simple supervised baseline on Yelp, AG News, Yahoo, and MNLI datasets.
Motivation
In machine learning tasks that involve categorical targets, it's traditional to one-hot code targets and use a cross-entropy loss to supervise a model. Problematically, models typically have no inherent notion of what each output class represents – the target classes' representations must be learned solely from their class members. This means:
- Classifier performance at initialization is no better than random and target model weights may need to move far from their initialization to achieve good performance.
- Especially in the low-data regime, spurious correlations within a given target class could adversely impact a models ability to generalize to the test set.
Key Contribution
How might we remedy these issues and leverage smaller labeled training sets to achieve better performance on downstream tasks?
The authors propose to:
- Reframe classification and natural language inference tasks as language modeling tasks with constrained outputs
- Finetune the model on the constrained language modeling task using a small pool of labeled data
- Use the language modeling task to soft-label an unlabeled training set
- Use a supervised, cross-entropy objective to train a classifier on the combined pool of ground truth and soft labels
Framing the problem as a text generation task allows an extra opportunity for the machine learning practitioner to specify the intended task to the machine learning model and inject some beneficial inductive bias.
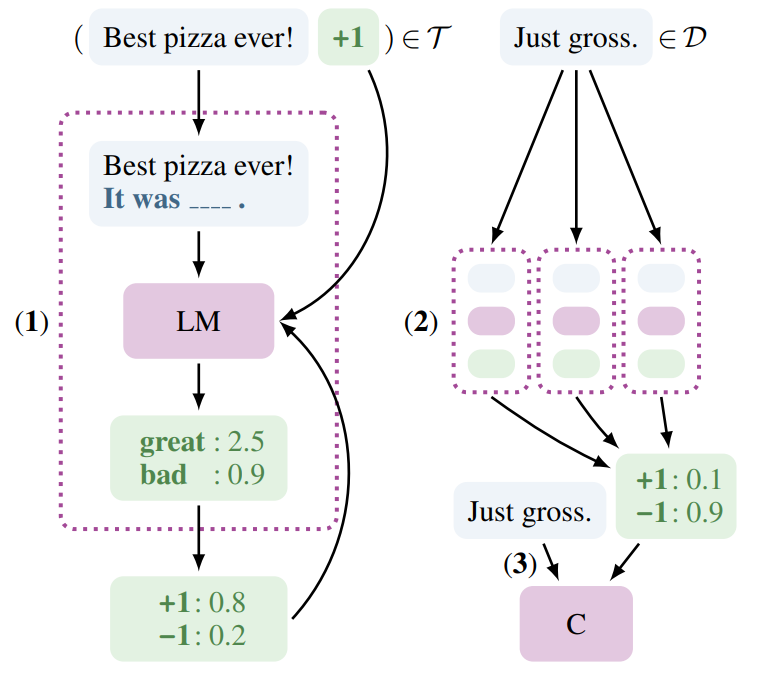
Reframing Supervised Tasks as Language Modeling Style Tasks
To the best of my knowledge, the idea of framing classification tasks as language-model completion tasks was first introduced in the paper that introduced GPT, "Improving Language Understanding by Generative Pre-Training".
To test their hypothesis that language models implicitly learn to solve many structured tasks in learning to minimize the language modeling loss, the OpenAI team tested the GPT model in a zero-shot setting on the Stanford Sentiment Treebank by appending the word "very" to the end of each example and determining whether the model assigns higher likelihood to the word "positive" or "negative" appearing as the next token.
Similarly, the authors of "Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer" reframe the target tasks in the GLUE benchmark as text generatior tasks to make use of their encoder-decoder language model, T5.
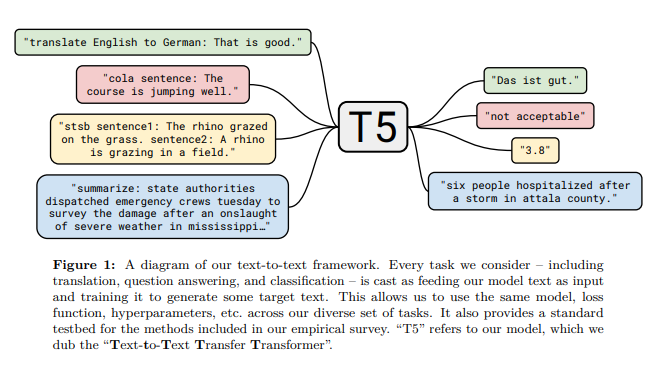
So the general idea of reframing classification tasks as language generation tasks isn't new – but PET provides empirical results that this approach is tractable and contributes a host of original additions that increase its effectiveness.
Zero-Shot Setting
For a concrete example, consider the Yelp sentiment analysis task. To exploit the knowledge already present in the language model, the authors use a "pattern" – a textual template for the language model to fill. In the following example, {text} represents the input text of a given example, and the blank corresponds to a masked token in a masked language modeling objective:
It was ____. {text}
For a given pattern, the authors compute likelihoods for a set of "verbalizers" using a softmax over the language models logits. In the case of Yelp – which uses a 1-5 star rating as its target – the authors selected the following to correspond to each of the 5 gradations.
- "terrible"
- "bad"
- "okay"
- "good"
- "great"
By taking a softmax over the logits of the verbalizer terms and masking all other terms, a probability distribution over target classes \(q_p(l \vert x)\), can be computed even in the absence of any labeled training data. They use the textual pattern and their set of verbalizers to reframe the classification task as a text generation task that is more closely aligned with the model's pre-training objective.
Finetuning on Labeled Training Data
With access to some small amount of labeled training data, we can supervise our model to improve its performance by penalizing the cross entropy between the output probability distribution over the verbalizers and each example's true label.
Note that this isn't dramatically different from the traditional language model finetuning procedure. The only differences are that:
- The model's output is conditioned on some additional text that helps to convey the task of interest.
- A
[mask]token is used in place of a newly initialized[clf]token – and occurs inline with the input text. - The final linear projection down to the number of target classes is initialized to the projections that correspond to our verbalizers terms, which act as class prototypes.
Extension to Multiple Patterns and Semi-Supervised Setting
Timo Shick and Hinrich Schütze further extend this framework to allow the use of multiple patterns. We'll return to our Yelp example to illustrate. Below, the || symbol represents the use of a [SEP] token to denote a boundary between two sequences, like was used in the BERT next sentence prediction task. In place of a single pattern, four are used:
- It was ____. {text}
- {text}. All in all, it was ____.
- Just ____! || {text}
- {text} || In summary, the restaurant was ____.
For each pattern:
- A model is finetuned on available labeled training data using the finetuning strategy above.
- The model predicts on all available unlabeled training data and logits are stored.
The output logits of all pattern-specific models can then be ensembled using a weighted mean to produce a soft label for each unlabeled example.
Finally, a single model is finetuned on the joint pool of ground-truth data and soft labels using standard finetuning methods (a classifier token and cross-entropy objective).
In this way, PET can exploit access to unlabeled training data to improve target model performance.
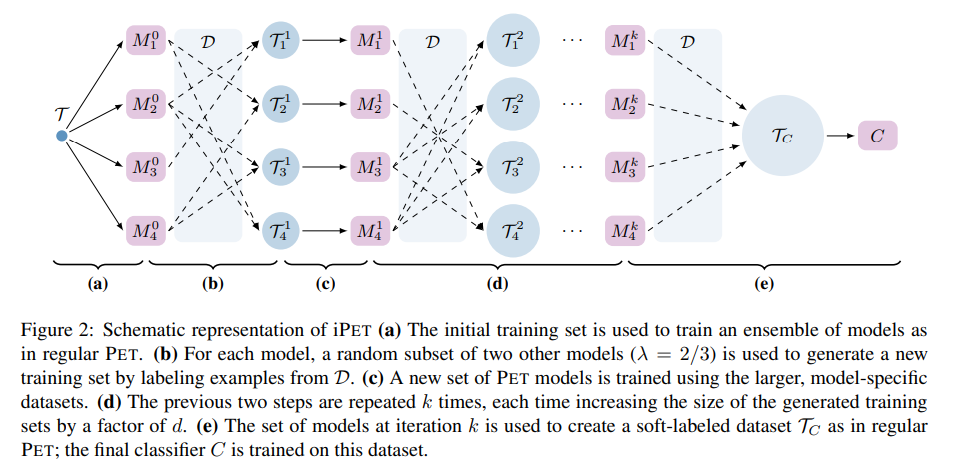
iPET
Rather than using the entirety of the unlabeled training data in one fell swoop, the author's also propose a modification to their Pattern-Exploiting Training method they call Iterative Pattern-Enhanced Training (iPET), which trains a series of model "generations".
- Available labeled training data is used to train an initial model for each pattern.
- The next-generation model for each pattern receives soft-labels on a fraction of the unlabeled data from an ensemble of the other pattern models from the previous generation. The likehood that a given example is included in the soft-labels is proportional to the model's confidence on that example.
- The process is repeated and progressively larger pools of soft-labels are produced until all available unlabeled data has soft-labels.
- Like in standard PET, a final model is finetuned on the joint pool of hard and soft targets.
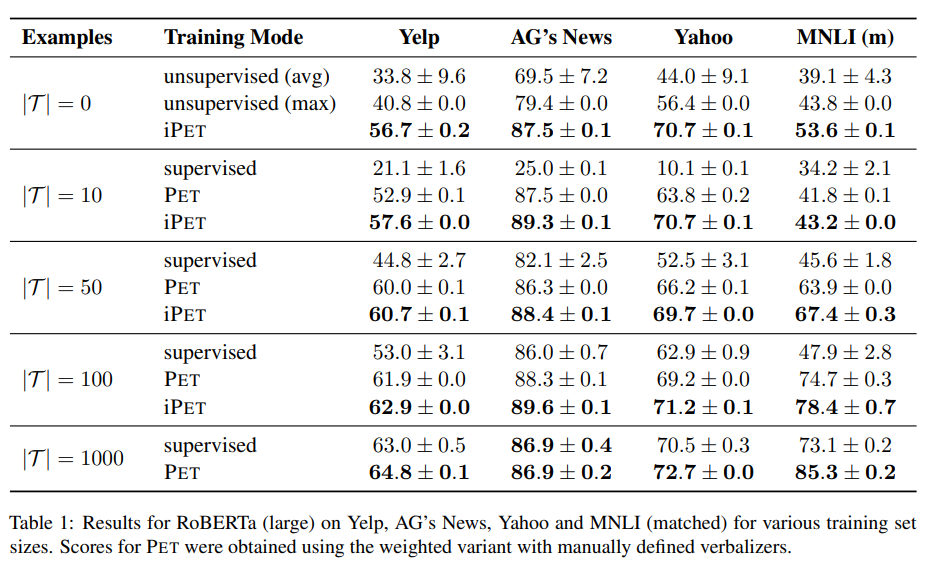
Experimental Results
The empirical results for the PET and iPET are impressive, especially at the lower extremes of labeled data availability. At 50 examples, iPET leads supervised training by ~16 points on Yelp, ~6 points on AG News, ~9 points on Yahoo, and ~22 points on MNLI.
Notably, even at 1000 examples there's a 12 point gap between PET and traditional supervised training on MNLI.
Further Experiments + Limitations
Continued pre-training
Shick and Schütze find that the PET methodology stacks additively with continued language model pre-training on in-domain data at low volumes of labeled training data, although the effect diminishes with increased training data availability.
Automatic Selection of Verbalizers
The authors devise a method for automatic verbalizer selection using minimal labeled training data, but find that it generally underperforms their manual verbalizer selections.
Finetuning Cost
Use of an ensemble of patterns (and a large pool of unlabeled examples) means that PET may require an order of magnitude more compute compared to a simple supervised baseline. iPET's model generation structure requires several finetuning and prediction stages, which also increases the computational requirements of training using the PET framework.
Final Thoughts
In spite of the increased cost of training, I think this paper makes an impactful contribution as labeled training data typically comes at a higher premium than increased access to compute in industry settings, and the performance increase over the supervised baselines are impressively large for Yelp, Yahoo, and MNLI.
I also appreciate that this work gives non-technical subject matter experts an additional interface for conveying their domain knowledge to a machine learning model. I'm adamant that there's a wealth of opportunity in finding more effective ways to specify tasks to machine learning models rather than simply relying on the benefits of data and model scale. How else might we design higher bandwidth methods for task specification?
If you'd like to play around with PET, the author's have exposed a clean interface to their research on Github based off of the Hugging Face transformers library.
References
- Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference by Timo Schick and Hinrich Schütze.
- Improving Language Understanding by Generative Pre-Training by by Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever
- "Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer" by Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu


