
This week I've decided to dive deep into a little known paper by Oren Melamud, Mihaela Bornea, and Ken Barker of IBM Research. Rather than focusing on how well deep learning models perform in the limits of training data, their work explores "low-shot learning" – an area of machine learning research that aims to learn usable models with limited training data.
In their work "Combining Unsupervised Pre-training and Annotator Rationales to Improve Low-shot Text Classification", they argue that using annotated "rationales" as auxiliary supervision signal can dramatically improve model performance when limited labeled training data is available. In this case, "rationales" simply means highlighted snippets of text that an annotator indicated informed their classification decision.
Spurious Correlation
The intuition for this difference is rather simple – when trying to learn a mapping from a long sequence of text to a singular class label, there may be many input features (or hidden states) correlated with the target class. Of these, some percentage are correlated by simple chance. Yet classifiers trained by SGD are indiscriminate of cause – they simply observe relationships and adjust their weights accordingly – so many of these statistical artifacts are unintentionally baked into our model after training. Our classifier requires explicit instruction that certain portions of our input are not typically correlated with our target variable in order to learn to ignore those signals.
Let's speak about a concrete example to illustrate – let's say we're tasked with determining the sentiment of movie reviews and are given a random sample of 10 documents (10 positive, 10 negative) to use as training data. What if, by simple chance, 5 of our 10 documents in the negative category contain the word "comedy", while none of the documents in the positive category do? Our model is ignorant of the task we're trying to solve – it can only observe the two sets of data we've provided it with and try to discriminate between the two to the best of its ability. The presence of the word "comedy" tells us nothing about the movie reviewers experience, and no movie warrants a negative review simply because it's part of the comedy genre (unless it also features Adam Sandler, in which case it's objectively bad). Even though the term "comedy" should not inform a classification decision, our model will observe the correlation and rate test documents that contain the word "comedy" more negatively.
Systemic Bias in Datasets
In our prior example the spurious correlation was merely an artifact of a small sample size. But that's not to say that this is a problem unique to the small data regime. Larger datasets may very well exhibit systematic bias because of the way they were acquired or created. Perhaps a dataset has been sampled from a specific time frame or source, or perhaps the bias has been introduced through over-aggressive preprocessing and filtering. Modern transformer-based architectures seem to be quite adept at exploiting these artifacts to produce benchmark gains.
An article published in The Gradient by Benjamin Heinzerling argues that "NLP's Clever Hans Moment Has Arrived", referencing an early 1900s horse presumed to be trained to solve logical and arithmetic tasks that was found to be picking up on unintentional body language cues from its trainer to identify the correct answer. Models are producing the right answers for (at least in part) the wrong reasons.

Timothy Niven and Hung-Yu Kao explore this phenomenon in their paper, "Probing Neural Network Comprehension of Natural Language Arguments". After applying BERT to the Argument Reasoning Comprehension Task, they reach an accuracy of just 77% – a meager three points behind the baseline! But looking behind the curtain and probing the relationships learned by the model reveals that surface level statistics (like unigrams and bigram frequencies) can be exploited to do better than random, and it's primarily through this exploitation that BERT is able to perform well on the ARC task (not through nuanced understanding and the application of logical reasoning). Simply using the presence of the word "not", for instance, is sufficient to achieve 61% accuracy on the 64% of the dataset that the heuristic applies to. Tom McCoy, Ellie Pavlic, and Tal Linzen show that this phenomon isn't unique to ARC in their paper Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference. The Multi-Genre NLI Corpus (MLNI) – included in the GLUE Benchmark Leaderboard – can be exploited in a similar manner.
Although the Clever Hans article concludes that the datasets we use to benchmark progress in the field of NLP need more love, I'd argue for that this is at least in part due to providing inadequate supervision to our machine learning models. If your goal is to produce a model capable of solving a specific task (rather than probing an existing model to understand what it has learned), we should seek more information rich methods of instruction. In other words, perhaps instead of criticizing our "students" for gaming the system we should seek to become better "teachers".
Annotator Rationales for Improved Classification
Now that the motivation for more information-rich supervision is clear, let's dive into the specifics of the paper at hand. The paper explores two distinct model architectures for leveraging the rationale information – "Rationale-biased Bag-of-words" and "Rationale-based BERT". "Rationale" in this case means a highlighted segment of text from which the annotator's decision was informed.

Rationale-biased Bag-of-words
For the bag-of-words baseline, the paper defines the input representation of each example to be a weighted sum of word vectors.
$$\vec{x_i} = \frac{1}{N}\sum_{i=1}^N w_i \vec{v_i}$$
The nuance is in how we compute the weights. Intuitively, we want words that look similar to our rationales to be assigned high weights.
Let's call each contiguous highlighted sequence a "rationale", and it's representation will simply be the normalized mean of it's word embeddings.
$$\vec{r_i} = \frac{1}{N}\sum_{i=1}^N\vec{v_i}$$
We'll also define a "prototype" rationale representation for each of our classes. This is a singular vector that summarizes the typical rationale for a given class, and is given by the mean of the rationales for that class.
$$\vec{R} = \frac{1}{N}\sum_{i=1}^N\vec{r_i}$$
They additionally encourage that rationales are distinct per class by subtracting the prototype vector of all rationales regardless of class from each classes prototype representation.
$$\vec{R_c} = \vec{R_c} - \vec{R}$$
To determine a token's weight, they take the maximum cosine similarity of a token's vector to the rationale prototype of any class.
$$sim(\vec{v}) = \max_{{c \in 1..k}} \frac{\vec{v} \cdot \vec{R_c}}{\lVert \vec{v} \rVert \lVert \vec {R_c} \rVert}$$
Finally, the similarities are scaled by a constant and they compute the softmax over all token weights in a given example in order to ensure an output with a consistent magnitude.
$$w_i = \frac{e^{\alpha \cdot sim(\vec{v_i})}}{\sum_{j=1}^N{e^{\alpha \cdot sim(\vec{v_i})}}}$$
The \(\alpha\) parameter serves to control the sharpness of the softmax output. Setting \(\alpha=0.\) enforces uniform weighting over tokens, while higher \(\alpha\) increases the weight of tokens that are aligned with rationales relative to other tokens. The select their \(\alpha\) parameter using a CV sweep.
With this setup, "training" is as simple as embedding the examples in the training set using this methodology and computing a mean. At test time, "prediction" is just the selection of the class whose mean is best aligned with an unseen examples embedding. No SGD required! Yet despite (or perhaps, due to) it's simplicity the method outperforms BERT finetuning until around 100 examples, and achieves 75% accuracy on the IMBD sentiment benchmark with a mere 20 examples. The rationales provide clear value over baseline even with this simplistic setup – an unweighted similarity consistently under-performed the rationale-weighted baseline by about 10 percentage points in a sweep from 20 to 500 training examples.
Rationale-biased BERT
For their BERT baseline, the authors separately embed each sentence and take an unweighted mean over the sentence embeddings. The mean of the sentence representations is then fed into a classification head added to the BERT base model.
$$L_{\text{total}} = L_{\text{classification}} + L_{\text{rationale}}$$
For it's rationale-informed counterpart, they use a multi-task learning framework and add an auxiliary rationale prediction loss to their classification loss. They take a mean of the likelihoods the rationale-head of the model assigns to each token (\(t_i\)) and use this mean as a sentence weight.
$$w_i = \frac{1}{N} \sum_{i=1}^N P_\text{rationale}(t_i) $$
The authors then compute a weighted sum of sentence representations, \(S_i\), for each document, \(D_i\). This aligns with a hypothesis that some sentences in a text example may be descriptive but unaligned with the target class.
$$D_i = \sum_{i=1}^K w_i S_i $$
Finally, the document representation is fed through a linear classifier to compute the classification prediction and corresponding cross-entropy loss.
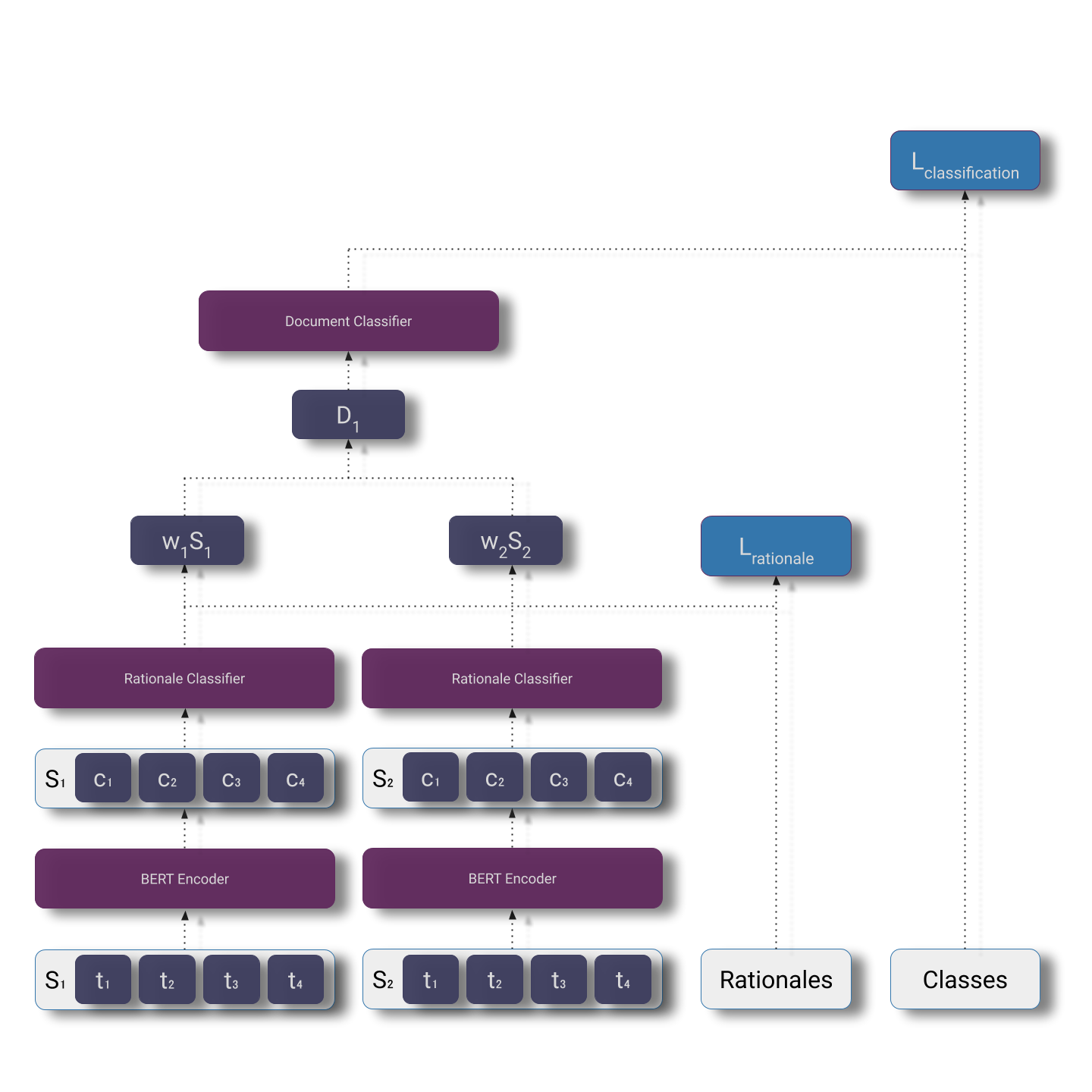
Although this architecture engineering may seem heavy handed (and a more flexible + general architecture may be preferable), the authors argue that this more bespoke architecture engineering is required when little training data is available. In other words, when labeled training data is scarce, encoding stronger inductive biases into the model architecture complements the more information-rich supervision by more narrowly specifying the space of solutions a model can discover.
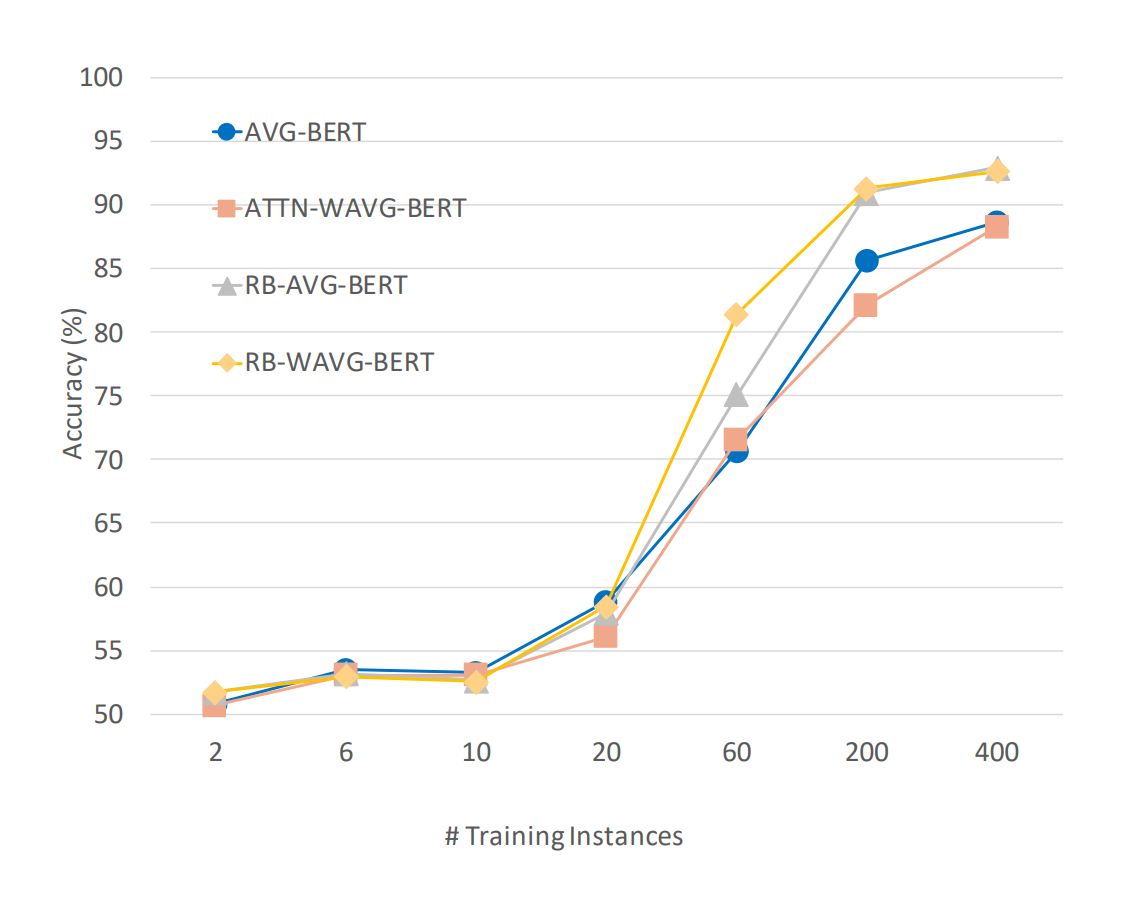
Like the bag-of-word baseline, the version of the model architecture that re-weights proportionally to the likelihood of a term being a valid rationale outperforms it counterpart by a substantial margin.
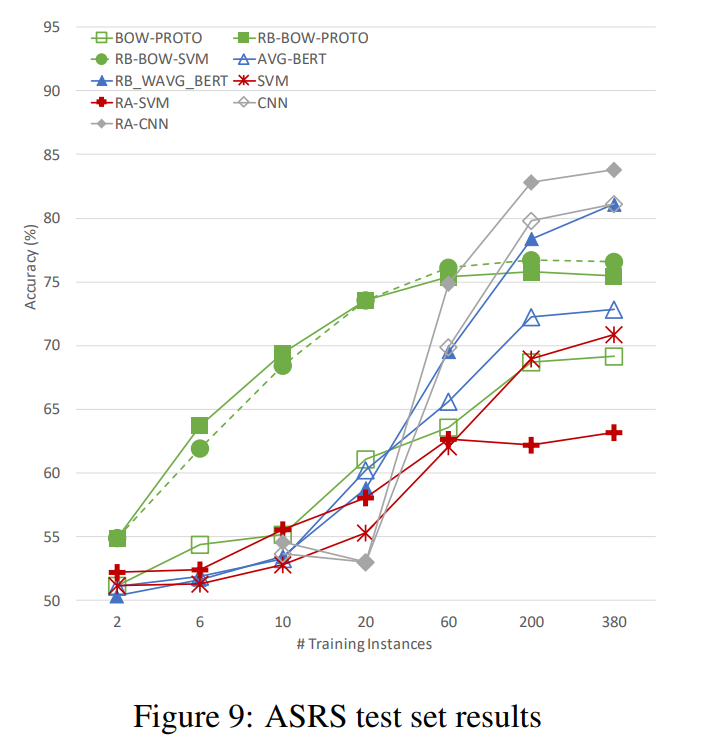
Their rationale-informed method also posted strong results at lower training data volumes on the Aviation Safety Report System (ASRS) dataset, although it was outperformed by other methods at larger training dataset sizes. Perhaps the strong inductive biases incorporated into the model architecture that lead to such strong performance at lower data volumes also led to the more sharp drop off as labeled training data availability increased.
Broader Applications
It's tempting to think of machine learning as a pure optimization problem. We're given data and tasked with finding the underlying patterns that govern the data's behavior. Yet some of these constraints are artificially imposed. In much of academic research, the dataset fed to a machine learning system is a fixed variable – it's the one constant in the system that can't be changed, so researchers work to devise better strategies to learn from the fixed dataset.
If our goal is to build more effective tools for accelerating manual and time intensive processes, however, the easiest route to improvement is often to build a better dataset rather than to spend too many cycles iterating on model architecture. In industry, when a model fails to achieve the desired performance on a task we first look to improve the dataset, as the data represents the communication layer between machine learning practitioner and model. When we're looking to build effective machine learning solutions to point problems, we primarily have a specification problem.
A brief thought experiment – let's say you're given a classification dataset with 50 long-form text examples. You aren't given a prompt, and the targets have already been one-hot encoded so you're unaware of the text of the labels. You're fully unaware of the task the dataset's creator has intended and can only learn do your best to ascertain the rules the dataset's creator has followed to separate the documents into classes. You have no prior over the space of possible tasks the dataset's creator might want to solve. Given this setting, it's not that surprising that most models perform poorly at low sample sizes when there exists so much natural ambiguity in the task's specification. How can we specify how we'd like a task to be solved with as little data (and human effort) as possible?
Simply providing class labels makes for a pleasant user experience, but can we find other methods of providing supervision that allow for learning more meaningful representations when abundant unlabeled data is not available? What if we explicitly annotated portions of the input we found to be partially contradictory to a labeling decision? Or perhaps a short textual description of a rationale could be leveraged in conjunction with a pre-trained language model to the end of more sample efficient learning? What if we included a textual prompt as a component of the training data and explicitly conditioned the models predictions on that text? Maybe, as the Snorkel team suggests, we could communicate task-relevant information to models via collections of simple heuristics provided in addition to typical labeled training data?
Although it leaves me with more questions than answers, I'm happy to see research that goes against the grain and explores some atypical methods for providing supervision signal, and am hopeful that as the field begins to emphasize concepts like interpretability more heavily, we'll see further research into this space. As a research community we've invested a substantial chunk of time into developing more powerful and flexible model architectures – let's invest at least a fraction of that effort into designing more effective and sample-efficient means of task specification.


