
This week we're diving into a paper published in early March 2020 – "Talking-Heads Attention" by Noam Shazeer, Zhenzhong Lan, Youlong Cheng, Nan Ding, and Le Hou that proposes a multi-head attention variant where information is allowed to pass between heads. They apply their modifications on top of BERT and the recently proposed T5 and Albert model architectures, and note improvements across the board on SQUAD 1.1 and a subset of the GLUE benchmark.
This summary is unique in that it comes bundled with recommended listening – the rock band "Talking Heads" 1983 hit "Burning Down the House". Put in your headphones, jam out to some funky music and read about an equally funky variation on multi-head attention.
Notation
Although the focus of the Talking-Heads Attention paper is a multi-head attention modification, the notation used in the paper is notable. Clear notation helps reduce the mental overhead spent on keeping track of tensor shapes and axis order, and I think the notation Noam Shazeer uses accomplishes this nicely. He employs a variant of einsum notation where the axes of the operation are referenced using named indexes, and the output shape of every operation is always explicitly specified.
# Matrix multiplication
Y[a, c] = einsum(X[a, b], W[b, c])
I was hoping to translate this notation to executable code, but this exact syntax won't function without a hefty dose of python black magic, so I tried to adhere to the style of Noam Shazeer's syntax instead without exactly replicating things.
a, b, c = (Axis('a'), Axis('b'), Axis('c'))
X = NamedTensor(x, axes=[a, b])
W = NamedTensor(w, axes=[b, c])
Y = named_einsum(X[a, b], W[b, c], out=[a, c])
If you'd like to execute this code for yourself, you can follow along in a colab notebook containing prototypes of Axis, NamedTensor, named_einsum, named_softmax and the code examples from this blog post. Note that this is a toy implementation – it will break down if you stray too far from the operations we use in the examples below.
Using this Notation for Multi-Head Self-Attention
Let's briefly review multi-head attention so that it's clear what is novel about the talking-heads variant. In code form, we first define the axes and tensors we'll use in our computation, then describe how the tensors should be combined in our multi_head_attention function. The P_q, P_k, P_v, and P_o matrices represent the parameters of our query, key, value, and output projections. The value M, the sequence we attend to, is set to the same value as X, our input sequence, as we're implementing self-attention. Random matrices are used as illustration.
import numpy as np
from numpy.random import randn
# Defining our axes
n = Axis('source_sequence', 512)
m = Axis('target_sequence', 512)
d_X = Axis('hidden_dim', 768)
d_K = Axis('key_dim', 64)
d_V = Axis('value_dim', 64)
h = Axis('n_heads', 12)
# Defining our tensors
inputs = randn(n, d_X)
X = NamedTensor(inputs, axes=[n, d_X])
M = NamedTensor(inputs, axes=[m, d_X])
P_q = NamedTensor(randn(d_X, d_K, h), axes=[d_X, d_K, h])
P_k = NamedTensor(randn(d_X, d_K, h), axes=[d_X, d_K, h])
P_v = NamedTensor(randn(d_X, d_V, h), axes=[d_X, d_V, h])
P_o = NamedTensor(randn(d_X, d_V, h), axes=[d_X, d_V, h])
def multi_head_attention(X, M, P_q, P_k, P_v, P_o):
# Query, key, and value projections
Q = named_einsum(X[n, d_X], P_q[d_X, d_K, h], out=[n, d_K, h])
K = named_einsum(M[n, d_X], P_k[d_X, d_K, h], out=[n, d_K, h])
V = named_einsum(M[n, d_X], P_v[d_X, d_V, h], out=[n, d_V, h])
# Logits
L = named_einsum(Q[n, d_K, h], K[m, d_K, h], out=[n, m, h])
# Attention weights
W = named_softmax(L[n, m, h], axis=m)
# Combine attention weights and projected values
O = named_einsum(W[n, m, h], V[m, d_V, h], out=[n, d_V, h])
# One final linear projection to produce our output
Y = named_einsum(O[n, d_V, h], P_o[d_X, d_V, h], out=[n, d_X])
return Y
print(multi_head_attention(X, M, P_q, P_k, P_v, P_o).shape)
# (512, 768)
We can visualize this sequence of operations below. The blue blocks represent the projections performed by our linear projection matrices and the white blocks represent intermediate state. Pink blocks represent parameter-less computation performed on intermediate states.

Talking-Heads Attention
Let's contrast our prior diagram with talking-heads attention. The first difference to note is the introduction of some new Axis definitions. We now have a separate Axis defined for the heads of our keys, values, and logits. By decoupling these values we can experiment with varying these dimensions independently and start to draw empirical conclusions about where we benefit most from the increased computation.
# Previously defined axes
n = Axis('source_sequence', 512)
m = Axis('target_sequence', 512)
d_X = Axis('hidden_dim', 768)
d_K = Axis('key_dim', 64)
d_V = Axis('value_dim', 64)
# New / modified axes
h_K = Axis('n_key_heads', 12)
h_V = Axis('n_value_heads', 12)
h = Axis('n_logit_heads', 12)You'll also note that we've added two more tensors – P_l and P_w. Each new tensor represents the parameters of a linear projection. The first, P_l, will be used to blend the query-key agreement values prior to our softmax operation. The second, P_w, will be used to blend the post-softmax attention weights prior to computing a weighted sum with our values.
# Previously defined tensors
inputs = randn(n, d_X)
X = NamedTensor(inputs, axes=[n, d_X])
M = NamedTensor(inputs, axes=[m, d_X])
P_q = NamedTensor(randn(d_X, d_K, h_K), axes=[d_X, d_K, h_K])
P_k = NamedTensor(randn(d_X, d_K, h_K), axes=[d_X, d_K, h_K])
P_v = NamedTensor(randn(d_X, d_V, h_V), axes=[d_X, d_V, h_V])
P_o = NamedTensor(randn(d_X, d_V, h_V), axes=[d_X, d_V, h_V])
# New tensors
P_l = NamedTensor(randn(h_K, h), axes=[h_K, h])
P_w = NamedTensor(randn(h, h_V]), axis=[h_V, h])
Adding these two linear projections into our multi_head_attention function, we get our new talking_heads_attention function.
def talking_heads_attention(X, M, P_q, P_k, P_v, P_o, P_l, P_w):
# Query, key, and value projections
Q = named_einsum(X[n, d_X], P_q[d_X, d_K, h_K], out=[n, d_K, h_K])
K = named_einsum(M[n, d_X], P_k[d_X, d_K, h_K], out=[n, d_K, h_K])
V = named_einsum(M[n, d_X], P_v[d_X, d_V, h_V], out=[n, d_V, h_V])
# Measure of query-key agreement
J = named_einsum(Q[n, d_K, h_K], K[m, d_K, h_K], out=[n, m, h_K])
# NEW: blend query-key agreement with talking-heads projection
L = named_einsum(J[n, m, h_K], P_l[h_K, h], out=[n, m, h])
# Attention weights
W = named_softmax(L[n, m, h], axis=m)
# NEW: blend attention-weights with secondary projection
U = named_einsum(W[n, m, h], P_w[h, h_V], out=[n, m, h_V])
# Combine attention weights and projected values
O = named_einsum(W[n, m, h], V[m, d_V, h], out=[n, d_V, h])
# One final linear projection to produce our output
Y = named_einsum(O[n, d_V, h], P_o[d_X, d_V, h], out=[n, d_X])
return Y
print(talking_heads_attention(X, M, P_q, P_k, P_v, P_o, P_l, P_w).shape)
# (512, 768)
Visually, this looks like the following. The new blue blue block prior and post our softmax block are the newly added talking heads projections.

Parameter Efficiency and Memory Complexity
The talking-heads module adds very few actual parameters to our attention module – we only need to store a total of h_K * h + h_V * h more parameters per attention layer. At typical numbers of heads – say, fixing our head axes all to 12 – this amounts to a mere 288 additional parameters per layer. Even if you increase the number of heads to 48 each, we still only require 4608 additional floats in each attention block.
Our memory complexity is not as nice, as the attention logits quickly become a memory bottleneck in transformer models as sequence length increases, and we've added two additional activations whose memory use also scales with the square of sequence length. This requires n * m * (h_K + h_V) additional activations per layer, which becomes problematic as the number of heads increases. The original paper didn't mention this increase in memory use but it means scaling up to sequences of more than 512 tokens would likely require some combination of gradient checkpoint or gradient accumulation in order to maintain large batch sizes during training.
Computational Efficiency
The number of floating point multiplications required also grows relatively quickly with respect to the number of heads used. Talking-heads attention requires an extra n * m * h * (h_K + h_V) multiplications per layer in addition to operations required for a standard multi-head attention operation. This is similar to the n * m * h * (d_K + d_V) term of standard attention, so it's easy to compare their relative expenses. When the number of heads (h_K, h_V) is smaller than the dimension per head (d_K, d_V), the additional computational complexity of the talking-heads attention is minimal. But when the number of heads increases past the size per head the computation required by the talking-heads projections becomes the dominating factor. There's also the issue that we're dealing with small matrices applied across many locations – a scenario that modern accelerator hardware isn't well suited to handling efficiently.
Experimental Results
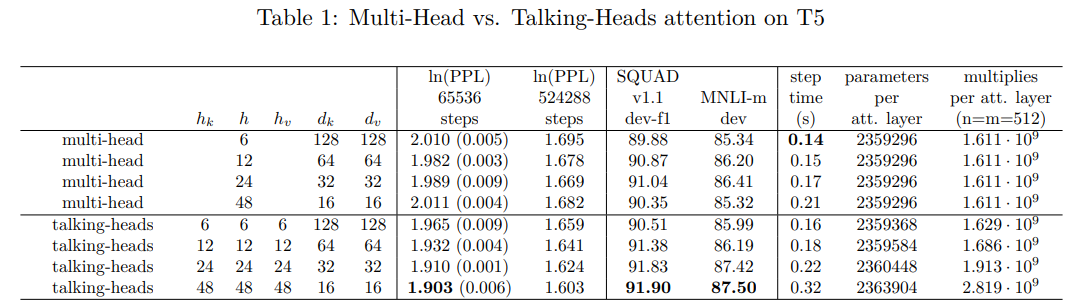
How well do models use this added flexibility to solve downstream tasks? According to downstream benchmarks, quite well. The authors used a T5 base model (from "Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer") and compared it to a talking-head augmented counterpart. Talking-heads based models consistently outperformed their multi-head attention counterparts in terms of perplexity as well as performance on SQUAD 1.1 and MNLI.
I very much appreciate that the authors also opted to highlight the runtime implications of their model architecture change in spite of the less than flattering numbers – the authors are clear that their downstream task improvements comes at a price and are direct about the cost rather than hoping the reader glosses over the detail.
The best performing model was the one with the least desirable performance characteristics and the maximum number of heads, at a count of 48 for each of the three head counts. This model variant clocked in about 65% the speed of it's multi-head attention counterpart. However, a more modest allocation of 24 heads each resulted in around 80% of the steps per second with a gap of 0.8 F1 and 1.0 match score on SQUAD and MNLI-m respectively.
Ablations
In order to test the sensitivity of the talking-heads attention model to various ablations, the authors ran several ablations. The results are summarized below:
- Increasing the number of softmax heads,
h, matters more thanh_Korh_V, although performance improves when increasing any of the three values. - The pre-softmax project and post-softmax projections are roughly equally important – removing either harms downstream task performance.
- Other model architectures (ALBERT and BERT) show similar trends to the T5 base model.
Conclusions
Is the added computational and memory complexity worth it? Perhaps – like any question worth asking, it depends on the context. If runtime or memory are no object, it's absolutely a step in the right direction. I'd be interested to see whether talking-heads attention would allow for better downstream task performance when controlling for step time by reducing hidden size or context length.
If you enjoyed the concise ideas from "Talking-Heads Attention", you'll likely enjoy reading some of Noam Shazeer's other works, including "Fast Transformer Decoding: One Write-Head is All You Need" and "GLU Variants Improve Transformer". They're consistently concise and well written – thoroughly testing a simple improvement and running rigorous ablations to better understand it's method of action. Performance is always front and center: the entire machine learning community should aspire to this variety of honest and transparent academic reporting.


